2026/01/27
少ないデータでも高精度な推論を実現するAI技術
1、店舗別にすると、なぜ売上予測は当たらなくなるのか?
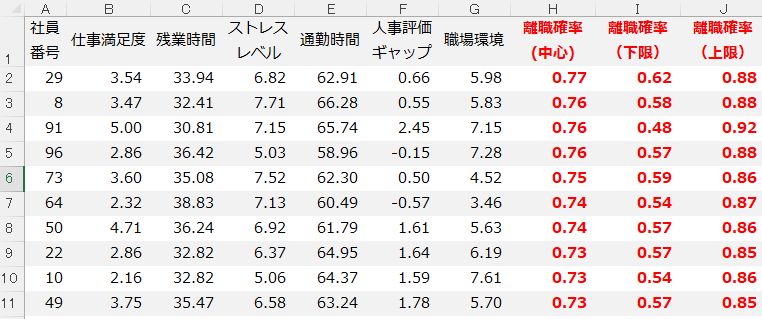
全社では数百のデータ点あるが、店舗別では 36個のデータ点(3年)しかない。
→これが通常のAI予測モデル(LightGBM・ランダムフォレストなど)が不安定になる理由です。
本部全体で見れば、売上データは何百か月分もあります。しかし、店舗ごとに分けた瞬間、状況は一変します。
1店舗あたりのデータはせいぜい36か月分(3年)で、季節・天候・販促などの影響も大きいことなどから、たった数回の異常値で、結果が大きく変わります。
この状態でよく使われるAI予測モデル(LightGBM や ランダムフォレストなど)を使うと、月ごとに予測がブレる、少し条件が変わると極端な数字が出るなどが起こり、「なぜそうなるのか説明できない」といった状況が発生しがちです。
2、「当たるかどうか分からない予測」は、現場では使えない
仮に「来月の売上は 1,200万円です」と言われても、本当にそのくらい売れそうなのか?外れたらどれくらいズレるのか?少なめに見積もるべきか、攻めてよいのか?といったことがが分からなければ、発注量、人員配置、シフト計画、販促の強さ、といった実務判断には使えません。
現場が本当に知りたいのは、「いくらくらいになりそうか」だけではなく、「どのくらい自信を持っていい数字なのか」です。
3、36か月のデータで、何が分かれば意思決定が楽になるのか?
そこで考えるべき予測の形は、次のようなものです。
・入力:店舗ID、月次来店数、月次販促費、平均気温
・出力:来月売上とその上下限(例:95%の確率で収まりそうな範囲)
つまり、「来月は 1,100万〜1,300万円 くらいになりそう、でも、上振れ・下振れの可能性はこれくらい」という形で分かることが重要です。
4、予測に「幅」があると、判断が一気にしやすくなる
予測に幅があると、下限に合わせて発注を抑えたり、上限を見て人員を厚めにする、不確実性が大きい月は販促を控える、といった現実的な判断ができます。
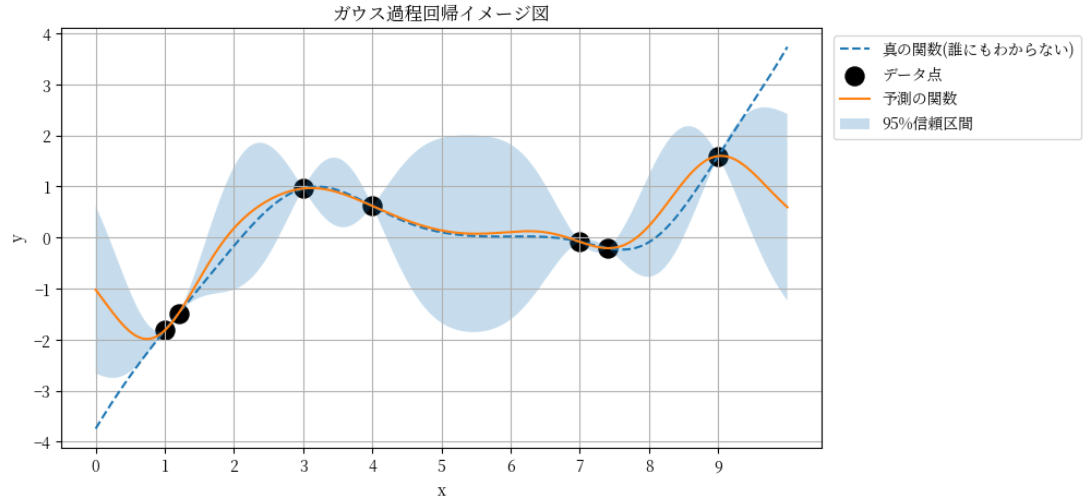
5、少ないデータでも、こうした予測ができる理由
このような考え方に向いているのが、ガウス過程回帰モデルという数理モデルです。
このモデルは、データが少ない前提で作られている、「分からない部分は分からない」と正直に示す、予測値と同時に、不確実性も計算できる、という特徴があり、大量データが前提のAIとは、そもそもの設計思想が違います。
貴社の店舗データ(36点)で成立するか、事前に確認できます
すべてのケースで使えるわけではありません。だからこそ、データ量、ばらつき、判断に使いたい目的(タスク)を見たうえで、「このやり方が成立するかどうか」を事前に診断することが重要です。貴社の店舗別データ(36か月分)でこの予測が成立するかを確認できます。
ご依頼は下記までお問合せください。
一般社団法人 社会整備サポート協会 https://social-navi.jp/contact/
参考資料:AIの答えが「教科書的」になる理由と汎用AIが自社専用にならない理由
参考資料:AIでリスクを予見・内部統制を強化
参考資料:少数データでAI分析
自然言語処理AI技術・生成AI技術を使ったAIメール解析システム Mail Beacon-1を開発